HDL Block Properties: General
Overview
Block implementation parameters enable you to control details of the code generated for specific block implementations. See Set and View HDL Model and Block Parameters to learn how to select block implementations and parameters in the GUI or the command line.
Property names are specified as character vectors. The data type of a property value is specific to the property. This section describes the syntax of each block implementation parameter and how the parameter affects generated code.
HDL Block Properties of Library Blocks
HDL block properties of library blocks are treated similar to mask parameters. When you instantiate library blocks in your model, the current HDL block properties of that library block are copied to instances of that block in your model. The HDL block properties of these instances are not synchronized with the HDL block properties of the library block. That is, if you change the HDL block property of the library block, the change does not get propagated to instances of the library block that you already added to your Simulink® model. If you want the HDL block properties of a library block to be synchronized with its instances in the model, create a Subsystem and then place this block inside that Subsystem. The HDL block properties of blocks that reside inside the library block are synchronized with the corresponding instances in your model.
Suppose a library contains a Subsystem block with HDL architecture set
to Module. When you instantiate this block in your model, the block
instance uses Module as the HDL architecture. If you change the HDL
architecture of the Subsystem block in the library to
BlackBox, existing instances of that Subsystem block
in your model still use Module as the HDL architecture. If you now add
instances of the Subsystem block from the library in your model, the new
block instances get a copy of the current HDL block properties, and therefore use
BlackBox as the HDL architecture. If you want the HDL architecture of
the Subsystem block in the library to be synchronized with its instances in
the model, create a wrapper subsystem with the HDL architecture that you want inside this
Subsystem.
AdaptivePipelining
The AdaptivePipelining subsystem parameter enables you to set
adaptive pipelining on a subsystem within a model.
| Adaptive Pipelining Setting | Description |
|---|---|
'inherit' (default) | Use the adaptive pipelining setting of the parent subsystem. If this subsystem is the highest-level subsystem, use the adaptive pipelining setting for the model. |
'on' | Insert adaptive pipelines for this subsystem. |
'off' | Do not insert adaptive pipelines for this subsystem, even if the parent subsystem has adaptive pipelining enabled. |
To disable adaptive pipelining for a subsystem within a model, set the adaptive
pipelining parameter, AdaptivePipelining, to 'off'
for that subsystem.
To learn how to set model-level adaptive pipelining, see Adaptive pipelining.
Set Adaptive Pipelining For a Subsystem
To set adaptive pipelining for a subsystem from the HDL Block Properties dialog box:
Right-click the subsystem and select HDL Code > HDL Block Properties.
For AdaptivePipelining, select inherit, on, or off.
To set adaptive pipelining for a subsystem from the command line, use
hdlset_param. For example, to turn off adaptive pipelining for a
subsystem, my_dut:
hdlset_param('my_dut', 'AdaptivePipelining', 'off')
hdlset_param.BalanceDelays
The BalanceDelays subsystem parameter enables you to set delay
balancing on a subsystem within a model.
| BalanceDelays Setting | Description |
|---|---|
'inherit' (default) | Use the delay balancing setting of the parent subsystem. If this subsystem is the highest-level subsystem, use the delay balancing setting for the model. |
'on' | Balance delays for this subsystem. |
'off' | Do not balance delays for this subsystem, even if the parent subsystem has delay balancing enabled. |
To disable delay balancing for any subsystem within a
model, you must set the model-level delay balancing parameter,
BalanceDelays, to 'off'. When delay balancing is
enabled on the model, the delay balancing setting on individual subsystems is
ignored.
To learn how to set model-level delay balancing, see Balance delays.
Set Delay Balancing For a Subsystem
To set delay balancing for a subsystem using the HDL Block Properties dialog box:
Right-click the subsystem.
Select HDL Code > HDL Block Properties .
For BalanceDelays, select inherit, on, or off.
To set delay balancing for a subsystem from the command line, use
hdlset_param. For example, to turn off delay balancing for a
subsystem, my_dut:
hdlset_param('my_dut', 'BalanceDelays', 'off')
hdlset_param.ClockRatePipelining
The ClockRatePipelining subsystem parameter enables you to set
clock-rate pipelining on a subsystem within a model.
| Clock-Rate Pipelining Setting | Description |
|---|---|
'inherit' (default) | Use the clock-rate pipelining setting of the parent subsystem. If this subsystem is the highest-level subsystem, use the clock-rate pipelining setting for the model. |
'on' | Insert clock-rate pipelines for this subsystem. |
'off' | Do not insert clock-rate pipelines for this subsystem, even if the parent subsystem has clock-rate pipelining enabled. |
To disable clock-rate pipelining for a subsystem within a model, set the clock-rate
pipelining parameter, ClockRatePipelining, to 'off'
for that subsystem.
To learn how to set model-level clock-rate pipelining, see Clock-rate pipelining.
Set Clock-Rate Pipelining For a Subsystem
To set clock-rate pipelining for a subsystem using the HDL Block Properties dialog box:
Right-click the subsystem.
Select HDL Code > HDL Block Properties .
For ClockRatePipelining, select inherit, on, or off.
To set clock-rate pipelining for a subsystem from the command line, use
hdlset_param. For example, to turn off clock-rate pipelining for a
subsystem, my_dut:
hdlset_param('my_dut', 'ClockRatePipelining', 'off')
hdlset_param.CodingStyle
When you use Multiport Switch blocks, use the
CodingStyle parameter to specify whether you want to generate HDL
code with if-else or case statements. By default, HDL Coder™ generates if-else statements. If you have several Multiport
Switch blocks in your model, you can choose to specify a different
CodingStyle for each block.
| CodingStyle Setting | Description |
|---|---|
'ifelse_stmt'(Default) | Generate if-else statements in the Verilog code or when-else statements in the VHDL code for a Multiport Switch block. |
'case_stmt' | Generate case statements in the Verilog code or case-when statements in the VHDL code for a Multiport Switch block. |
Set CodingStyle For Multiport Switch Block
To set CodingStyle for a Multiport Switch using the HDL Block Properties dialog box:
Right-click the Multiport Switch block.
Select HDL Code > HDL Block Properties .
For CodingStyle, select
ifelse_stmtorcase_stmt.
To see the CodingStyle specified for a subsystem from the command
line, use hdlget_param. For example, to see the settings specified
for a Multiport Switch block inside a subsystem,
my_dut:
hdlget_param('my_dut/Multiport Switch', 'CodingStyle')
ans =
'case_stmt'hdlset_param.ConstMultiplierOptimization
The ConstMultiplierOptimization implementation parameter lets you
specify use of canonical signed digit (CSD) or factored CSD optimizations for processing
coefficient multiplier operations in the generated code.
The following table shows the ConstMultiplierOptimization
parameter values.
| ConstMultiplierOptimization Setting | Description |
|---|---|
'none'(Default) | By default, HDL Coder does not perform CSD or FCSD optimizations. Code generated for the Gain block retains multiplier operations. |
'CSD' | When you specify this option, the generated code decreases the area used by the model while maintaining or increasing clock speed, using canonical signed digit (CSD) techniques. CSD replaces multiplier operations with add and subtract operations. CSD minimizes the number of addition operations required for constant multiplication by representing binary numbers with a minimum count of nonzero digits. |
'FCSD' | This option uses factored CSD (FCSD) techniques, which replace multiplier operations with shift and add/subtract operations on certain factors of the operands. These factors are generally prime but can also be a number close to a power of 2, which favors area reduction. This option lets you achieve a greater area reduction than CSD, at the cost of decreasing clock speed. |
'auto' | When you specify this option, HDL Coder chooses between the CSD or FCSD optimizations. The coder chooses the
optimization that yields the most area-efficient implementation, based on the
number of adders required. When you specify |
The ConstMultiplierOptimization parameter is available for the
following blocks:
Gain
Stateflow® chart
Truth Table
MATLAB Function
MATLAB System
ConstrainedOutputPipeline
Use the ConstrainedOutputPipeline parameter to specify a
nonnegative number of registers to place at the block outputs.
HDL Coder moves existing delays within your design to try to meet your constraint. New registers are not added. If there are fewer registers than the coder needs to satisfy your constraint, the coder reports the difference between the number of desired and actual output registers. You can add delays to your design using input or output pipelining.
Distributed pipelining does not redistribute registers you specify with constrained output pipelining.
How to Specify Constrained Output Pipelining
To specify constrained output pipelining for a block using the GUI:
Right-click the block and select HDL Code > HDL Block Properties.
For ConstrainedOutputPipeline, enter the number of registers you want at the output ports.
To specify constrained output pipelining, at the command line, enter:
hdlset_param(path_to_block,
'ConstrainedOutputPipeline', number_of_output_registers)subsys, in your model, mymodel,
enter:hdlset_param('mymodel/subsys','ConstrainedOutputPipeline', 6)
See Also
DistributedPipelining
The DistributedPipelining parameter enables pipeline register
distribution, a speed optimization that enables you to increase your clock speed by reducing
your critical path.
The following table shows the effect of the
DistributedPipelining and OutputPipeline
parameters.
| DistributedPipelining | OutputPipeline, nStages | Result |
|---|---|---|
'off' (default) | Unspecified (nStages defaults to 0) | HDL Coder does not insert pipeline registers. |
nStages > 0 | The coder inserts nStages output registers at the
output of the subsystem, MATLAB Function block, or Stateflow chart. | |
'on'
| Unspecified (nStages defaults to 0) | The coder does not insert pipeline
registers.DistributedPipelining has
no effect. |
nStages > 0 | The coder distributes nStages registers inside the
subsystem, MATLAB Function block, or Stateflow chart, based on critical path analysis. |
To achieve further optimization of code generated with distributed pipelining, perform retiming during RTL synthesis, if possible.
Tip
Output data might be in an invalid state initially if you insert pipeline registers. To avoid test bench errors resulting from initial invalid samples, disable output checking for those samples. For more information, see Ignore output data checking (number of samples).
See Also
DotProductStrategy
If you use the Product block for matrix multiplication in
your design, use the DotProductStrategy to specify how you want to
implement the matrix multiplication.
The DotProductStrategy options are listed in the following
table.
| DotProductStrategy Value | Description |
|---|---|
'Fully Parallel' (default) | Expands the matrix multiplication operation into multipliers and adders. For example, if you multiply two 2x2 matrices, the implementation uses eight multipliers and four adders to compute the result. Note The DotProductStrategy must be set to |
'Serial Multiply-Accumulate' | Uses the Serial architecture of the Multiply-Accumulate block to implement the matrix multiplication. In this architecture, the clock rate must be faster than the clock rate that you specify with Parallel architecture. You can see the clock rate in the Clock Summary information of the Code Generation report. |
'Parallel Multiply-Accumulate' | Uses the Parallel architecture of the Multiply-Accumulate block to implement the matrix multiplication. |
DSPStyle
DSPStyle enables you to generate code that includes synthesis
attributes for multiplier mapping in your design. You can choose whether to map a particular
block’s multipliers to DSPs or logic in hardware.
For Xilinx® targets, the generated code uses the use_dsp attribute.
For Altera® targets, the generated code uses the multstyle attribute.
The DSPStyle options are listed in the following
table.
| DSPStyle Value | Description |
|---|---|
'none' (default) | Do not insert a DSP mapping synthesis attribute. |
'on' | Insert synthesis attribute that directs the synthesis tool to map to DSPs in hardware. |
'off' | Insert synthesis attribute that directs the synthesis tool to map to logic in hardware. |
The DSPStyle parameter is available for the following blocks:
Gain
Product
Product of Elements with Architecture set to Tree
Subsystem
Atomic Subsystem
Variant Subsystem
Enabled Subsystem
Triggered Subsystem
Model with Architecture set to
ModelReference
Hierarchy Flattening Behavior
If you specify hierarchy flattening for a subsystem that also has a nondefault
DSPStyle setting, HDL Coder propagates the DSPStyle setting to the parent
subsystem.
If the flattened subsystem contains Gain, Product, or
Product of Elements blocks, the coder keeps their nondefault
DSPStyle settings, and replaces default
DSPStyle settings with the flattened subsystem
DSPStyle setting.
Synthesis Attributes in Generated Code
The generated code for synthesis attributes depends on:
Target language
DSPStylevalueSynthesisToolvalue
The following table shows examples of synthesis attributes in generated code.
| DSPStyle Value | TargetLanguage Value | SynthesisTool Value | |
|---|---|---|---|
'Altera Quartus II' | 'Xilinx
ISE''Xilinx Vivado' | ||
'none' | 'Verilog' |
|
|
'VHDL' |
|
| |
'on' | 'Verilog' |
|
|
'VHDL' |
|
| |
'off' | 'Verilog' |
|
|
'VHDL' |
|
| |
Requirement For Synthesis Attribute Specification
You must specify a synthesis tool by using the SynthesisTool
property.
How To Specify a Synthesis Attribute
To specify a synthesis attribute using the HDL Block Properties dialog box:
Right-click the block.
Select HDL Code > HDL Block Properties .
For DSPStyle, select on, off, or none.
To specify a synthesis attribute from the command line, use
hdlset_param. For example, suppose you have a model,
my_model, with a DUT subsystem, my_dut, that
contains a . Gain block, my_multiplier. To insert a synthesis attribute
to map my_multiplier to a DSP,
enter:
hdlset_param('my_model/my_dut/my_multiplier', 'DSPStyle', 'on')
hdlset_param.Limitations For Synthesis Attribute Specification
When you specify a nondefault
DSPStyleblock property, theConstMultiplierOptimizationproperty must be set to'none'.Inputs to multiplier components cannot use the
doubledata type.Gain constant cannot be a power of 2.
FlattenHierarchy
FlattenHierarchy enables you to remove subsystem hierarchy from the
HDL code generated from your design.
| FlattenHierarchy Setting | Description |
|---|---|
'inherit' (default) | Use the hierarchy flattening setting of the parent subsystem. If this subsystem is the highest-level subsystem, do not flatten. |
'on' | Flatten this subsystem. |
'off' | Do not flatten this subsystem, even if the parent subsystem is flattened. |
To flatten hierarchy, you must also have the MaskParameterAsGeneric
global property set to 'off'. For more information, see Generate parameterized HDL code from masked subsystem.
How To Flatten Hierarchy
To set hierarchy flattening using the HDL Block Properties dialog box:
In the Apps tab, select HDL Coder. The HDL Code tab appears. Select the Subsystem and then click HDL Block Properties. For FlattenHierarchy, select on, off, or inherit.
Right-click the Subsystem and select HDL Code > HDL Block Properties. For FlattenHierarchy, select on, off, or inherit.
To set hierarchy flattening from the command line, use hdlset_param.
For example, to turn on hierarchy flattening for a subsystem, my_dut:
hdlset_param('my_dut', 'FlattenHierarchy', 'on')
hdlset_param.Limitations For Hierarchy Flattening
A subsystem cannot be flattened if the subsystem is:
A Synchronous Subsystem or uses the State Control block in
Synchronousmode.A model reference implementation.
A Triggered Subsystem when Use trigger signal as clock is enabled.
A masked subsystem that contains any of the following:
Bus.
Enumerated data type.
Lookup table blocks: 1-D Lookup Table, 2-D Lookup Table, Cosine HDL Optimized, Direct LookupTable (n-D), Prelookup, Sine HDL Optimized, n-D Lookup Table.
MATLAB System block.
Stateflow blocks: Chart, State Transition Table, Sequence Viewer.
Blocks with a pass-through or no-op implementation. See Pass through, No HDL, and Cascade Implementations.
Note
This option removes subsystem boundaries before code generation. It does not necessarily generate HDL code with a completely flat hierarchy.
InputPipeline
InputPipeline lets you specify a implementation with input
pipelining for selected blocks. The parameter value specifies the number of input pipeline
stages (pipeline depth) in the generated code.
The following code specifies an input pipeline depth of two stages for each Sum block in the model:
sblocks = find_system(gcb, 'BlockType', 'Sum');
for ii=1:length(sblocks),hdlset_param(sblocks{ii},'InputPipeline', 2), end;
Note
The InputPipeline setting does not have
any effect on blocks that do
not have an input port.
When generating code for pipeline registers, HDL Coder appends a postfix string to names of input or output pipeline registers. The
default postfix string is _pipe. To customize the postfix string, use the
Pipeline postfix option in the Global Settings /
General pane in the HDL Code Generation pane of the
Configuration Parameters dialog box. Alternatively, you can pass the desired
postfix as a character vector in the makehdl
property PipelinePostfix. For an example, see Pipeline postfix.
InstantiateFunctions
For the MATLAB Function block, you can use the InstantiateFunctions parameter
to generate a VHDL® entity or Verilog® module for
each function. HDL Coder generates code for each entity or module in
a separate file.
The InstantiateFunctions options for the MATLAB Function block are listed in the following table.
| InstantiateFunctions Setting | Description |
|---|---|
'off' (default) | Generate code for functions inline. |
'on' | Generate a VHDL |
How To Generate Instantiable Code for Functions
To set the InstantiateFunctions parameter using the HDL Block Properties dialog box:
Right-click the MATLAB Function block.
Select HDL Code > HDL Block Properties.
For InstantiateFunctions, select on.
To set the InstantiateFunctions parameter
from the command line, use hdlset_param. For
example, to generate instantiable code for functions in a MATLAB
Function block, myMatlabFcn, in your DUT
subsystem, myDUT, enter:
hdlset_param('my_DUT/my_MATLABFcnBlk', 'InstantiateFunctions', 'on')Generate Code Inline for Specific Functions
If you want to generate instantiable code for some functions
but not others, enable the option to generate instantiable code for
functions, and use coder.inline. See coder.inline for details.
Limitations for Instantiable Code Generation for Functions
The software generates code inline when:
Function calls are within conditional code or
forloops.Any function is called with a nonconstant
structinput.The function has state, such as a persistent variable, and is called multiple times.
There is an enumeration anywhere in the design function.
InstantiateStages
For a Cascade architecture, you can use the
InstantiateStages parameter to generate a VHDL
entity or Verilog
module for each computation stage. HDL Coder generates code for each entity or module
in a separate file.
| InstantiateStages Setting | Description |
|---|---|
'off' (default) | Generate cascade stages in a single VHDL
|
'on' | Generate a VHDL
|
LoopOptimization
LoopOptimization enables you to stream or unroll loops in code
generated from a MATLAB Function block. Loop streaming optimizes for area;
loop unrolling optimizes for speed.
Note
If you specify the MATLAB Datapath architecture of the
MATLAB Function block, you can only unroll loops. To stream loops, you
can use the streaming optimization by specifying a StreamingFactor.
See HDL Optimizations Across MATLAB Function Block Boundary Using MATLAB Datapath Architecture.
| LoopOptimization Setting | Description |
|---|---|
'none' (default) | Do not optimize loops. |
'Unrolling' | Unroll loops. |
'Streaming' | Stream loops. |
How to Optimize MATLAB Function Block For Loops
To select a loop optimization using the HDL Block Properties dialog box:
Right-click the MATLAB Function block.
Select HDL Code > HDL Block Properties.
For LoopOptimization, select
none,Unrolling, orStreaming.
To select a loop optimization from the command line, use
hdlset_param. For example, to turn on loop streaming for a
MATLAB Function block, my_mlfn:
hdlset_param('my_mlfn', 'LoopOptimization', 'Streaming')
hdlset_param.Limitations for MATLAB Function Block Loop Optimization
HDL Coder cannot stream a loop if:
The loop index counts down. The loop index must increase by 1 on each iteration.
There are 2 or more nested loops at the same level of hierarchy within another loop.
Any particular persistent variable is updated both inside and outside a loop.
HDL Coder can stream a loop when the persistent variable is:
Updated inside the loop and read outside the loop.
Read within the loop and updated outside the loop.
LUTRegisterResetType
Use the LUTRegisterResetType block parameter to control synthesis
of a LUT into a ROM structure on an FPGA.
| LUTRegisterResetType Value | Description |
|---|---|
default | LUT output register has default reset logic. When you generate HDL, the LUT will be synthesized as registers. |
none | LUT output register has no reset logic. When you generate HDL, the LUT will be synthesized as a ROM. |
You can specify LUTRegisterResetType for the following
blocks:
Gamma Correction
Lookup Table
The NCO HDL Optimized block ignores this parameter.
MapPersistentVarsToRAM
With the MapPersistentVarsToRAM implementation parameter, you can
use RAM-based mapping for persistent arrays of a MATLAB Function block
instead of mapping to registers.
| MapPersistentVarsToRAM Setting | Mapping Behavior |
|---|---|
| Persistent arrays map to registers in the generated HDL code. |
| Persistent array variables map to RAM. For restrictions, see RAM Mapping Restrictions. |
RAM Mapping Restrictions
When you enable RAM mapping, a persistent array or user-defined System object™ private property maps to a block RAM when all of the following conditions are true:
Each read or write access is for a single element only. For example, submatrix access and array copies are not allowed.
Address computation logic is not read-dependent. For example, computation of a read or write address using the data read from the array is not allowed.
Persistent variables or user-defined System object private properties are initialized to 0 if they have a cyclic dependency. For example, if you have two persistent variables, A and B, you have a cyclic dependency if A depends on B, and B depends on A.
If an access is within a conditional statement, the conditional statement uses only simple logic expressions (
&&,||,~) or relational operators. For example, in the following code,r1does not map to RAM:if (mod(i,2) > 0) a = r1(u); else r1(i) = u; endRewrite complex conditions, such as conditions that call functions, by assigning them to temporary variables, and using the temporary variables in the conditional statement. For example, to map
r1to RAM, rewrite the previous code as follows:temp = mod(i,2); if (temp > 0) a = r1(u); else r1(i) = u; endThe persistent array or user-defined System object private property value depends on external inputs.
For example, in the following code,
bigarraydoes not map to RAM because it does not depend onu:function z = foo(u) persistent cnt bigarray if isempty(cnt) cnt = fi(0,1,16,10,hdlfimath); bigarray = uint8(zeros(1024,1)); end z = u + cnt; idx = uint8(cnt); temp = bigarray(idx+1); cnt(:) = cnt + fi(1,1,16,0,hdlfimath) + temp; bigarray(idx+1) = idx;RAMSizeis greater than or equal to theRAMMappingThresholdvalue.RAMSizeis the productNumElements * WordLength * Complexity.NumElementsis the number of elements in the array.WordLengthis the number of bits that represent the data type of the array.Complexityis 2 for arrays with a complex base type; 1 otherwise.
If any of the above conditions is false, the persistent array or user-defined System object private property maps to a register in the HDL code.
RAMMappingThreshold
The default value of RAMMappingThreshold is 256. To change the
threshold, use hdlset_param. For example, the following command
changes the mapping threshold for the sfir_fixed model to 128
bits:
hdlset_param('sfir_fixed', 'RAMMappingThreshold', 128);
You can also change the RAM mapping threshold in the Configuration Parameters dialog box. For more information, see RAM mapping threshold (bits) section in RAM Mapping Parameters.
Example
For an example that shows how to map persistent array variables to RAM in a MATLAB Function block, see RAM Mapping With the MATLAB Function Block.
OutputPipeline
OutputPipeline lets you specify a implementation with output
pipelining for selected blocks. The parameter value specifies the number of output pipeline
stages (pipeline depth) in the generated code.
The following code specifies an output pipeline depth of two stages for each Sum block in the model:
sblocks = find_system(gcb, 'BlockType', 'Sum');
for ii=1:length(sblocks),hdlset_param(sblocks{ii},'OutputPipeline', 2), end;
Note
The OutputPipeline setting does not have
any effect on blocks that do
not have an output port.
When generating code for pipeline registers, HDL Coder appends a postfix string to names of input or output pipeline registers. The
default postfix string is _pipe. To customize the postfix string, use the
Pipeline postfix option in the Configuration Parameters dialog box,
in the HDL Code Generation > Global Settings > General tab.
Alternatively, you can use the PipelinePostfix property with
makehdl. For an example, see Pipeline postfix.
See also Distributed Pipeline Insertion for MATLAB Function Blocks.
RAMDirective
RAMDirective lets you specify whether you want to map the RAM
blocks in your Simulink model to distributed RAMs, block RAMs, or UltraRAM memory. When you select a
value for this setting, HDL Coder generates a ramstyle attribute in the HDL code. This
attribute specifies the type of RAM memory unit that you want the synthesis tool to use when
inferring the RAM blocks in your design.
| RAMDirective Value | Description |
|---|---|
none (default) | Do not generate the |
distributed | Generate HDL attribute for mapping the RAM blocks in your model to distributed RAMs. Distributed RAMs are constructed with LUT. These RAMs are faster but occupy a larger number of LUT slices on the FPGA. This VHDL code
shows the attribute ram_style: string; attribute ram_style of ram : signal is "distributed"; This
Verilog code shows the (* ram_style = "distributed" *) |
block | Generate HDL attribute for mapping the RAM blocks in your model to block
RAMs. A block RAM is a dedicated memory unit on the FPGA device. The number of
block RAMs available depends on the FPGA device that you are deploying the HDL
code to. Sizes of block RAMs can be To map your RAM blocks to block RAM:
This VHDL code shows the attribute ram_style: string; attribute ram_style of ram : signal is "block"; This
Verilog code shows the (* ram_style = "block" *) |
ultra | Generate HDL attribute for mapping the RAM blocks in your model to
UltraRAM memory. An UltraRAM is a dedicated memory block on the target FPGA. The
number of UltraRAM memory units available depends on the FPGA device that you are
deploying the HDL code to. UltraRAM units are larger than block RAMs and can be as
large as To map your RAM blocks to UltraRAM:
This VHDL code shows the attribute ram_style: string; attribute ram_style of ram : signal is "ultra"; This
Verilog code shows the (* ram_style = "ultra" *) |
Set RAMDirective for RAM Blocks
In the HDL RAMs library, except for the Dual Rate Dual
Port RAM, you can specify the RAMDirective property for
all other RAM blocks.
To set RAMDirective for a RAM block from the HDL Block Properties
dialog box:
Right-click the RAM block.
Select HDL Code > HDL Block Properties .
For RAMDirective, select none, distributed, block, or ultra.
Note
For the Dual Port RAM block, you cannot specify
ultraas theRAMDirectivebecause the block does not have a fixed read behavior.
To set RAMDirective for a block from the command line, use
hdlset_param. For example, to set RAMDirective
to ultra for a Single Port RAM block inside a subsystem,
my_dut:
hdlset_param('my_dut/Single Port RAM', 'RAMDirective', 'ultra');
hdlset_param.ResetType
Use the ResetType block parameter to suppress reset logic
generation.
| ResetType Value | Description |
|---|---|
default | Generate reset logic. |
none | Do not generate reset logic. Reset is not applied to generated registers. Therefore, mismatches between Simulink and the generated code occur for some number of samples during the initial phase, when registers are not fully loaded. To avoid test bench errors during the initial phase, determine the number of samples required to fully load the registers. Then, set the Ignore output data checking (number of samples) option accordingly. See also Ignore output data checking (number of samples) in Test Bench Stimulus and Output Parameters. |
You can specify ResetType for the following blocks:
Chart
Convolutional Deinterleaver
Convolutional Interleaver
Delay
Delay (DSP System Toolbox™)
General Multiplexed Deinterleaver
General Multiplexed Interleaver
MATLAB Function
MATLAB System
Memory
Tapped Delay
Truth Table
Unit Delay Enabled
Unit Delay
Reset Logic for Optimizations in the MATLAB Function Block
When you set ResetType to none for a
MATLAB Function block, HDL Coder does not generate reset logic for persistent variables in the MATLAB® code.
However, if you specify other optimizations for the block, the coder may insert
registers that use reset logic. The coder does not suppress reset logic generation for
these registers. Therefore, if you set ResetType to
none along with other block optimizations, your generated
code may have a reset port at the top level.
How to Suppress Reset Logic Generation
To suppress reset logic generation for a block using the UI:
Right-click the block and select HDL Code > HDL Block Properties.
For ResetType, select
none.
To suppress reset logic generation, on the command line, enter:
hdlset_param(path_to_block,'ResetType','none')
For example, to suppress reset logic generation for a Unit Delay block,
UnitDelay1, within a subsystem, mySubsys, on the
command line, enter:
hdlset_param('mySubsys/UnitDelay1','ResetType','none');
Specify Synchronous or Asynchronous Reset
To specify a synchronous or asynchronous reset, use the ResetType
model-level parameter. For details, see Reset type in
Reset Settings and Parameters.
SerialPartition
Use this parameter on Min/Max blocks to specify partitions for a serial cascade architecture. The default setting uses the minimum number of partitions.
| To Generate This Architecture... | Set SerialPartition to... |
|---|---|
| Cascade-serial with explicitly specified partitioning | [p1 p2 p3...pN]: a vector of N integers,
where N is the number of serial partitions. Each element of the
vector specifies the length of the corresponding partition. The sum of the vector
elements must be equal to the length of the input data vector. The values of the
vector elements must be in descending order, except the last two elements can be
equal. For example, for an input of 8 elements, partitions [5 3]
or [4 2 2] are legal, but the partitions [2 2 2
2] or [3 2 3] raise an error at code generation time.
|
| Cascade-serial with automatically optimized partitioning | 0 |
This property is also used for serial filter architectures. For how to configure filter blocks, see SerialPartition.
SharingFactor
Use SharingFactor to specify the number of functionally equivalent
resources to map to a single shared resource. The default is 0. See Resource Sharing.
SoftReset
Use the SoftReset block parameter to specify whether to generate
hardware-friendly synchronous reset logic, or local reset logic that matches the Simulink
simulation behavior. This property is available for the Unit Delay Resettable
block or Unit Delay Enabled Resettable block.
| SoftReset Value | Description |
|---|---|
off (default) | Generate local reset logic that matches the Simulink simulation behavior. |
on | Generate synchronous reset logic for the block. This option generates code that is more efficient for synthesis, but does not match the Simulink simulation behavior. |
When SoftReset set to 'off', the following code
is generated for a Unit Delay Resettable block
:
always @(posedge clk or posedge reset)
begin : Unit_Delay_Resettable_process
if (reset == 1'b1) begin
Unit_Delay_Resettable_zero_delay <= 1'b1;
Unit_Delay_Resettable_switch_delay <= 2'b00;
end
else begin
if (enb) begin
Unit_Delay_Resettable_zero_delay <= 1'b0;
if (UDR_reset == 1'b1) begin
Unit_Delay_Resettable_switch_delay <= 2'b00;
end
else begin
Unit_Delay_Resettable_switch_delay <= In1;
end
end
end
end
assign Unit_Delay_Resettable_1 =
(UDR_reset ||
Unit_Delay_Resettable_zero_delay ? 1'b1 : 1'b0);
assign out0 = (Unit_Delay_Resettable_1 == 1'b1 ? 2'b00 :
Unit_Delay_Resettable_switch_delay);
When SoftReset set to 'on', the following code
is generated for a Unit Delay Resettable block
:
always @(posedge clk or posedge reset)
begin : Unit_Delay_Resettable_process
if (reset == 1'b1) begin
Unit_Delay_Resettable_reg <= 2'b00;
end
else begin
if (enb) begin
if (UDR_reset != 1'b0) begin
Unit_Delay_Resettable_reg <= 2'b00;
end
else begin
Unit_Delay_Resettable_reg <= In1;
end
end
end
end
assign out0 = Unit_Delay_Resettable_reg;
StreamingFactor
Number of parallel data paths, or vectors, to transform into serial, scalar data paths by time-multiplexing serial data paths and sharing hardware resources. The default is 0, which implements fully parallel data paths. See also Streaming.
UsePipelines
You can use this mode with Product blocks in Divide and
Reciprocal modes. This property becomes available when you set the HDL
architecture for the blocks to ShiftAdd. This architecture uses a
non-restoring division algorithm that performs multiple shift and add operations to compute
the quotient. The ShiftAdd architecture provides improved accuracy
compared to the Newton-Raphson approximation method.
When you use the ShiftAdd architecture, you can use the
UsePipelines implementation parameter to specify whether to use a
pipelined or non-pipelined implementation of the non-restoring division.
| UsePipelines Setting | Mapping Behavior |
|---|---|
| Use a pipelined implementation of the non-restoring shift and add operation for Divide and Reciprocal blocks. This setting adds more delays to your design but achieves a higher maximum clock frequency on the target FPGA device. The number of pipelines inserted matches the number of iterations that the algorithm requires to compute the quotient or reciprocal. |
| Use a non-pipelined implementation of the non-restoring shift and add
operation for Divide and Reciprocal blocks. This
setting does not add delays to your design. As division and reciprocal are
resource-intensive operations, to achieve higher clock frequencies on the target
FPGA, set UsePipelines to |
Set UsePipelines for Divide and Reciprocal Blocks
To set UsePipelines for a subsystem from the HDL Block Properties
dialog box:
Right-click the subsystem.
Select HDL Code > HDL Block Properties .
For UsePipelines, select on or off.
To set UsePipelines for a block from the command line, use
hdlset_param. For example, to turn off
UsePipelines for a Divide block inside a subsystem,
my_dut:
hdlset_param('my_dut/divide', 'UsePipelines', 'off');
hdlset_param.UseRAM
The UseRAM implementation parameter enables using RAM-based mapping
for a block instead of mapping to a shift register.
| UseRAM Setting | Mapping Behavior |
|---|---|
| The delay maps to a shift register in the generated HDL code, except in one case. For details, see Effects of Streaming and Distributed Pipelining. |
| The delay maps to a dual-port RAM block when the following conditions are true:
If any condition is false, the delay maps to a shift register in the HDL code unless it merges with other delays to map to a single RAM. For more information, see Mapping Multiple Delays to RAM. |
This implementation parameter is available for the Delay block in the Simulink Discrete library and the Delay (DSP System Toolbox) block in the DSP System Toolbox Signal Operations library.
Mapping Multiple Delays to RAM
HDL Coder can also merge several delays of equal length into one delay and then map the merged delay to a single RAM. This optimization provides the following benefits:
Increased occupancy on a single RAM
Sharing of address generation logic, which minimizes duplication of identical HDL code
Mapping of delays to a RAM when the individual delays do not satisfy the threshold
The following rules control whether or not multiple delays can merge into one delay:
The delays must:
Be at the same level of the subsystem hierarchy.
Use the same compiled sample time.
Have
UseRAMset toon, or be generated by streaming or resource sharing.Have the same
ResetTypesetting, which cannot benone.
The total word length of the merged delay cannot exceed 128 bits.
The
RAMSizeof the merged delay is greater than or equal to theRAMMappingThresholdvalue.RAMSizeis the productDelayLength * WordLength * VectorLength * ComplexLength.DelayLengthis the total number of delays.WordLengthis the number of bits that represent the data type of the merged delay.VectorLengthis the number of elements in a vector delay.VectorLengthis 1 for a scalar delay.ComplexLengthis 2 for complex delays; 1 otherwise.
Example of Multiple Delays Mapping to a Block RAM
RAMMappingThreshold for the following model is 100 bits.
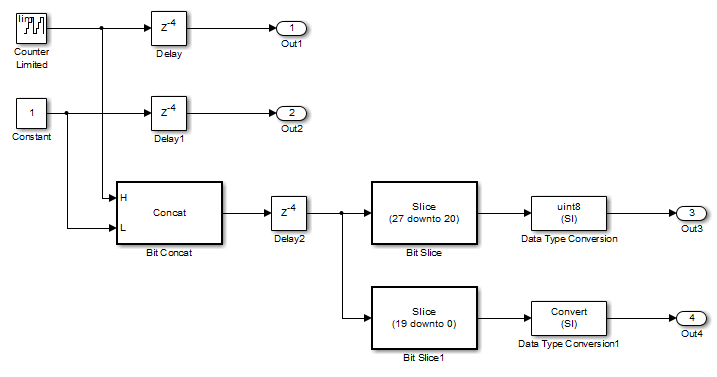
The Delay and Delay1 blocks merge and map to a dual-port RAM in the generated HDL code by satisfying the following conditions:
Both delay blocks:
Are at the same level of the hierarchy.
Use the same compiled sample time.
Have UseRAM set to
onin the HDL block properties dialog box.Have the same ResetType setting of
default.
The total word length of the merged delay is 28 bits, which is below the 128-bit limit.
The
RAMSizeof the merged delay is 112 bits (4 delays * 28-bit word length), which is greater than the mapping threshold of 100 bits.
When you generate HDL code for this model, HDL Coder generates additional files to specify RAM mapping. The coder stores these
files in the same source location as other generated HDL files, for example, the
hdlsrc folder.
Effects of Streaming and Distributed Pipelining
When UseRAM is off for a Delay block,
HDL Coder maps the delay to a shift register by default. However, the coder changes
the UseRAM setting to on and tries to map the
delay to a RAM under the following conditions:
Streaming is enabled for the subsystem with the Delay block.
Distributed pipelining is disabled for the subsystem with the Delay block.
Suppose that distributed pipelining is enabled for the subsystem with the Delay block.
When
UseRAMisoff, the Delay block participates in retiming.When
UseRAMison, the Delay block does not participate in retiming. HDL Coder does not break up a delay marked for RAM mapping.Consider a subsystem with two Delay blocks, three Constant blocks, and three Product blocks:
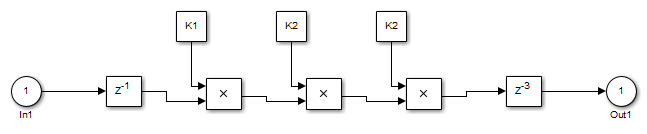
When
UseRAMisonfor the Delay block on the right, that delay does not participate in retiming.
The following summary describes whether or not HDL Coder tries to map a delay to a RAM instead of a shift register.
UseRAM Setting for the Delay
Block | Optimizations Enabled for Subsystem with Delay Block | ||
|---|---|---|---|
| Distributed Pipelining Only | Streaming Only | Both Distributed Pipelining and Streaming | |
| On | Yes | Yes | Yes |
| Off | No | Yes, because mapping to a RAM instead of a shift register can provide an area-efficient design. | No |
VariablesToPipeline
Warning
VariablesToPipeline is not recommended. Use coder.hdl.pipeline instead.
The VariablesToPipeline parameter enables you to insert a pipeline register at the output of one or more MATLAB variables. Specify a list of variables as a character vector, with spaces separating the variables.
See also Pipeline MATLAB Expressions.