Discrete FIR Filter HDL Optimized
Finite impulse response filter—optimized for HDL code generation
- Library:
DSP System Toolbox HDL Support / Filtering
Description
The Discrete FIR Filter HDL Optimized block models finite-impulse response filter architectures optimized for HDL code generation. The block accepts one input sample at a time, and provides an option for programmable coefficients. It provides a hardware-friendly interface with input and output control signals. To provide a cycle-accurate simulation of the generated HDL code, the block models architectural latency including pipeline registers and resource sharing.
The block provides three filter structures. The direct form systolic architecture provides a fully parallel implementation that makes efficient use of Intel® and Xilinx® DSP blocks. The direct form transposed architecture is a fully parallel implementation and is suitable for FPGA and ASIC applications. The partly serial systolic architecture provides a configurable serial implementation that makes efficient use of FPGA DSP blocks. For a filter implementation that matches multipliers, pipeline registers, and pre-adders to the DSP configuration of your FPGA vendor, specify your target device when you generate HDL code.
All three structures optimize hardware resources by sharing multipliers for symmetric or antisymmetric filters. The parallel implementations also remove the multipliers for zero-valued coefficients such as in half-band filters and Hilbert transforms.
The latency between valid input data and the corresponding valid output data depends on the filter structure, serialization options, the number of coefficients, and whether the coefficient values provide optimization opportunities. For details of structure and latency, see the Algorithm section.
For a FIR filter with multichannel or frame-based inputs, use the Discrete FIR Filter (Simulink) block instead of this block.
Ports
Input
Output
Parameters
Model Examples




Tips
Reset Behavior
By default, the Discrete FIR Filter HDL Optimized block connects the generated HDL global reset to only the control path registers. The two reset parameters, Enable reset input port and Use HDL global reset, connect a reset signal to the data path registers. Because of the additional routing and loading on the reset signal, resetting data path registers can reduce synthesis performance .
The Enable reset input port parameter enables the reset port on the block. The reset signal implements a local synchronous reset of the data path registers. For optimal use of FPGA resources, this option does not connect the reset signal to registers targeted to the DSP blocks of the FPGA.
The Use HDL global reset parameter connects the generated HDL global reset signal to the data path registers. This parameter does not change the appearance of the block or modify simulation behavior in Simulink. The generated HDL global reset can be synchronous or asynchronous depending on the HDL Code Generation > Global Settings > Reset type parameter in the model Configuration Parameters. Depending on your device, using the global reset might move registers out of the DSP blocks and increase resource use.
When you select the Enable reset input port and Use HDL global reset parameters together, the global and local reset signals clear the control and data path registers.
Reset Considerations for Generated Test Benches
FPGA-in-the-loop initialization provides a global reset but does not automatically provide a local reset. With the default reset parameters, the data path registers that are not reset can result in FPGA-in-the-loop (FIL) mismatches if you run the FIL model more than once without resetting the board. Select Use HDL global reset to reset the data path registers automatically, or select Enable reset input port and assert the local reset in your model so the reset signal becomes part of the Simulink FIL test bench.
The generated HDL test bench provides a global reset but does not automatically provide a local reset. With the default reset parameters and the default register reset Configuration Parameters, the generated HDL code includes an initial simulation value for the data path registers. However, if you are concerned about
X-propagation in your design, you can set the HDL Code Generation > Global Settings > Coding style > No-reset register initialization parameter in Configuration Parameters toDo not initialize. In this case, with the default block reset parameters, the data path registers that are not reset can causeX-propagation on the data path at the start of HDL simulation. Select Use HDL global reset to reset the data path registers automatically, or select Enable reset input port and assert the local reset in your model so the reset signal becomes part of the generated HDL test bench.
Algorithms
The block provides several filter implementations depending on your parameter settings. The filter implementation considers vendor-specific hardware details of the DSP blocks when adding pipeline registers to the architecture. These differences in pipeline register locations help fit the filter design to the DSP blocks on the FPGA.
The architecture diagrams assume a transfer function that has
L coefficients (before optimizations are
applied).
| Filter structure | Number of cycles (N) | Architecture and Performance Link |
|---|---|---|
Direct form systolic | N/A | Fully Parallel Systolic Architecture |
Direct form transposed | N/A | Fully Parallel Transposed Architecture |
Partly serial systolic | N < L | Partly Serial Systolic Architecture (1 < N < L) |
Partly serial systolic | N ≥ L | Fully Serial Systolic Architecture (N ≥ L) |
Complex Multipliers
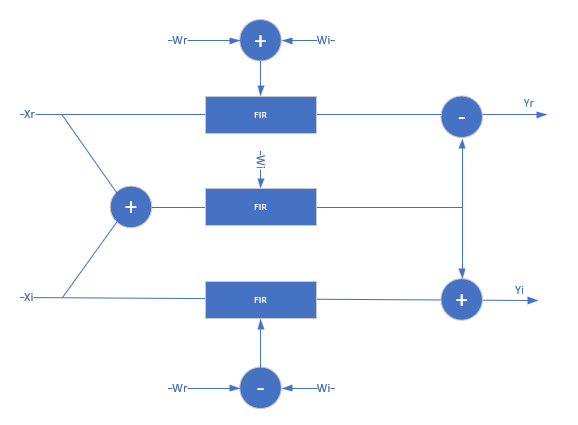
If either data or coefficients are complex but not both, the block implements one filter to calculate the real output and a second filter to calculate the imaginary part. This implementation results in two multipliers for each filter tap.
When both the data and coefficients are complex, the block implements three filters in parallel. The diagram show the filter implementation for complex input data X = Xr+i×Xi and complex coefficients W = Wr+i×Wi.

When Coefficients source is set to
Property,
Wr +
Wi and
Wr-Wi
are pre-calculated, so this implementation uses 3 DSP blocks for each filter
tap, plus the input adder and two output adders. The input to each filter
tap multiplier grows by one bit.
When Coefficients source is set to Input
port, the block uses 2 more adders for each filter tap.
These adders calculate the coefficients
Wr +
Wi and
Wr-Wi.
Fully Parallel Systolic Architecture
When you set the Filter structure parameter to
Direct form systolic, the block implements
a fully parallel systolic architecture with optimizations for symmetry or
anti-symmetry and zero-valued coefficients. The latency depends on the
coefficient symmetry and is displayed on the block icon.
When symmetric pairs of coefficients have equal absolute values, they share one DSP block. This pair-sharing enables the implementation to use the pre-adder in Xilinx and Intel DSP blocks. The top half of the diagram shows a symmetric filter without the pair coefficient optimization. The bottom half of the diagram shows the architecture using the pair coefficient optimization.

This table shows post-synthesis resource utilization for the HDL code
generated for a symmetric 26-tap FIR filter with 16-bit input and
16-bit coefficients. The synthesis targets a Xilinx ZC-706 (XC7Z045ffg900-2) FPGA. The Global HDL
reset type is Synchronous
and Minimize clock enables is selected. The
reset port is not enabled, so only control
path registers are connected to the generated global HDL reset.
| Resource | Uses |
|---|---|
| LUT | 36 |
| Slice Reg | 487 |
| Slice | 45 |
| Xilinx LogiCORE DSP48 | 13 |
After place and route, the maximum clock frequency of the design is 630 MHz.
Fully Parallel Transposed Architecture
When you set the Filter structure parameter to
Direct form transposed, the block
implements a fully parallel transposed architecture. This architecture
minimizes multipliers by sharing multipliers for any two or more
coefficients that have equal absolute values. It also removes multipliers
for zero-valued coefficients. The latency of the block is six cycles. This
latency does not change with coefficient values.
The top half of the diagram shows the theoretical architecture for a partly-symmetric filter without the equal-absolute-value coefficient optimization. The bottom half of the diagram shows the transposed architecture as implemented by this block, using the equal-value coefficient optimization. If the coefficients are antisymmetric, the output adder becomes a subtraction.
![]()
Partly Serial Systolic Architecture (1 < N < L)
When you set the Filter structure parameter to
Partly serial systolic, and you choose a
serialization factor, N, such that
N is less than the number of coefficients
but greater than one, the block implements a partly serial systolic
architecture. The serial implementation uses
M =
ceil(L/N)M lookup tables. The computation performed
by each DSP block is serialized. Input samples to the block must be at least
N cycles apart. The latency of the block is
M +
ceil( +
L/M)5.

This table shows post-synthesis resource utilization for the HDL code
generated from the Partly Serial Systolic FIR Filter Implementation example. The implementation is
for a 32-tap FIR filter with 16-bit input, 16-bit coefficients, and a
serialization factor of 8 cycles between valid input samples. The
synthesis targets a Xilinx Virtex-6 (XC6VLX240T-1FF1156) FPGA. The Global
HDL reset type is
Synchronous and Minimize
clock enables is selected.
| Resource | Uses |
|---|---|
| LUT | 192 |
| FFS | 606 |
| Xilinx LogiCORE DSP48 | 5 |
After place and route, the maximum clock frequency of the design is 376 MHz.
Fully Serial Systolic Architecture (N ≥ L)
When you set the Filter structure parameter to
Partly serial systolic, and you choose a
serialization factor such that
NLL coefficients. Input
samples must be at least N cycles apart. The
latency of the block is L +
5.
