findgroups
Find groups and return group numbers
Syntax
Description
G = findgroups(A)G,
a vector of group numbers created from the grouping variable A.
The output argument G contains integer values from
1 to N, indicating N distinct
groups for the N unique values in A.
For example, if A is {'b','a','a','b'},
then findgroups returns G as [2
1 1 2]. You can use G to split groups
of data out of other variables. Use G as an input
argument to splitapply in the Split-Apply-Combine Workflow.
findgroups treats empty character vectors
and NaN, NaT, and undefined
categorical values in A as missing values and returns NaN as
the corresponding elements of G.
G = findgroups(A1,...,AN)A1,...,AN. The findgroups function
defines groups as the unique combinations of values across A1,...,AN.
For example, if A1 is {'a','a','b','b'} and A2 is [0
1 0 0], then findgroups(A1,A2) returns G as [1
2 3 3], because the combination 'b' 0 occurs
twice.
[ also
returns the unique values for each group across G,ID1,...,IDN] = findgroups(A1,...,AN)ID1,...,IDN.
The values across ID1,...,IDN define the groups.
For example, if A1 is {'a','a','b','b'} and A2 is [0
1 0 0], then findgroups(A1,A2) returns G as [1
2 3 3], and ID1 and ID2 as {'a','a','b'} and [0
1 0].
Examples
Input Arguments
Output Arguments
More About
Split-Apply-Combine Workflow
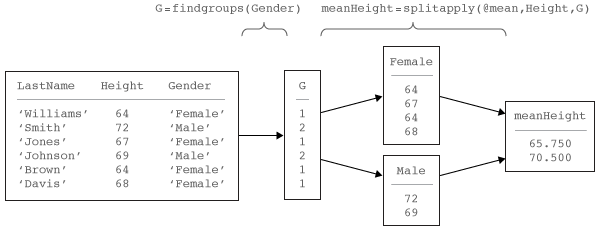
The Split-Apply-Combine workflow
is common in data analysis. In this workflow, the analyst splits the
data into groups, applies a function to each group, and combines the
results. The diagram shows a typical example of the workflow and the
parts of the workflow implemented by findgroups and splitapply.
Extended Capabilities
See Also
accumarray | arrayfun | convertvars | discretize | groupsummary | histcounts | ismember | rowfun | splitapply | unique | varfun | vartype