Translate
Translate image in 2-D plane using displacement vector
Library
Geometric Transformations
visiongeotforms

Description
Use the Translate block to move an image in a two-dimensional plane using a displacement vector, a two-element vector that represents the number of pixels by which you want to translate your image. The block outputs the image produced as the result of the translation.
Note
This block supports intensity and color images on its ports.
| Port | Input/Output | Supported Data Types | Complex Values Supported |
|---|---|---|---|
Image / Input | M-by-N matrix of intensity values or an M-by-N-by-P color video signal where P is the number of color planes |
| No |
Offset | Vector of values that represent the number of pixels by which to translate the image | Same as I port | No |
Output | Translated image | Same as I port | No |
The input to the Offset port must be the same data type as the input to the Image port. The output is the same data type as the input to the Image port.
Use the Output size after translation parameter to specify the size of
the translated image. If you select Full, the block outputs a
matrix that contains the entire translated image. If you select Same as
input image, the block outputs a matrix that is the same size as the
input image and contains a portion of the translated image. Use the Background
fill value parameter to specify the pixel values outside the
image.
Use the Offset source parameter to specify how to enter your displacement
vector. If you select Specify via dialog, the
Offset parameter appears in the dialog box. Use it to enter
your displacement vector, a two-element vector, [r c], of real,
integer values that represent the number of pixels by which you want to translate your
image. The r value represents how many pixels up or down to shift
your image. The c value represents how many pixels left or right to
shift your image. The axis origin is the top-left corner of your image. For example, if
you enter [2.5 3.2], the block moves the image 2.5 pixels
downward and 3.2 pixels to the right of its original location. When the displacement
vector contains fractional values, the block uses interpolation to compute the
output.
Use the Interpolation method parameter to specify which interpolation
method the block uses to translate the image. If you translate your image in either the
horizontal or vertical direction and you select Nearest
neighbor, the block uses the value of the nearest pixel for the new
pixel value. If you translate your image in either the horizontal or vertical direction
and you select Bilinear, the new pixel value is the weighted
average of the four nearest pixel values. If you translate your image in either the
horizontal or vertical direction and you select Bicubic, the
new pixel value is the weighted average of the sixteen nearest pixel values.
The number of pixels the block considers affects the complexity of the computation. Therefore, the nearest-neighbor interpolation is the most computationally efficient. However, because the accuracy of the method is roughly proportional to the number of pixels considered, the bicubic method is the most accurate. For more information, see Nearest Neighbor, Bilinear, and Bicubic Interpolation Methods in the Computer Vision Toolbox™ User's Guide.
If, for the Output size after translation parameter, you select
Full, and for the Offset source
parameter, you select Input port, the Maximum
offset parameter appears in the dialog box. Use the Maximum
offset parameter to enter a two-element vector of real, scalar values
that represent the maximum number of pixels by which you want to translate your image.
The block uses this parameter to determine the size of the output matrix. If the input
to the Offset port is greater than the Maximum offset parameter
values, the block saturates to the maximum values.
If, for the Offset source parameter, you select Input
port, the Offset port appears on the block. At each time step, the
input to the Offset port must be a vector of real, scalar values that represent the
number of pixels by which to translate your image.
Fixed-Point Data Types
The following diagram shows the data types used in the Translate block for bilinear interpolation of fixed-point signals.
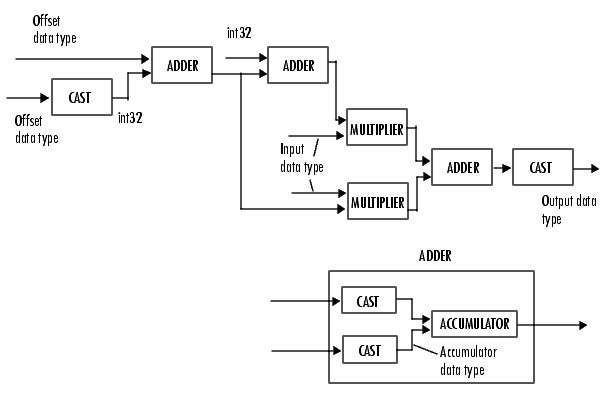
You can set the product output, accumulator, and output data types in the block mask as discussed in the next section.
Parameters
- Output size after translation
If you select
Full, the block outputs a matrix that contains the translated image values. If you selectSame as input image, the block outputs a matrix that is the same size as the input image and contains a portion of the translated image.- Offset source
Specify how to enter your translation parameters. If you select
Specify via dialog, the Offset parameter appears in the dialog box. If you selectInput port, port O appears on the block. The block uses the input to this port at each time step as your translation values.- Offset source
Enter a vector of real, scalar values that represent the number of pixels by which to translate your image.
- Background fill value
Specify a value for the pixels that are outside the image.
- Interpolation method
Specify which interpolation method the block uses to translate the image. If you select
Nearest neighbor, the block uses the value of one nearby pixel for the new pixel value. If you selectBilinear, the new pixel value is the weighted average of the four nearest pixel values. If you selectBicubic, the new pixel value is the weighted average of the sixteen nearest pixel values.- Maximum offset
Enter a vector of real, scalar values that represent the maximum number of pixels by which you want to translate your image. This parameter must have the same data type as the input to the Offset port. This parameter is visible if, for the Output size after translation parameter, you select
Fulland, for the Offset source parameter, you selectInput port.
- Rounding mode
Select the rounding mode for fixed-point operations.
- Overflow mode
Select the overflow mode for fixed-point operations.
- Offset values
Choose how to specify the word length and the fraction length of the offset values.
When you select
Same word length as input, the word length of the offset values match that of the input to the block. In this mode, the fraction length of the offset values is automatically set to the binary-point only scaling that provides you with the best precision possible given the value and word length of the offset values.When you select
Specify word length, you can enter the word length of the offset values, in bits. The block automatically sets the fraction length to give you the best precision.When you select
Binary point scaling, you can enter the word length and the fraction length of the offset values, in bits.When you select
Slope and bias scaling, you can enter the word length, in bits, and the slope of the offset values. The bias of all signals in the Computer Vision Toolbox blocks is 0.
This parameter is visible if, for the Offset source parameter, you select
Specify via dialog.- Product output
-

As depicted in the previous figure, the output of the multiplier is placed into the product output data type and scaling. Use this parameter to specify how to designate this product output word and fraction lengths.
When you select
Same as first input, these characteristics match those of the first input to the block.When you select
Binary point scaling, you can enter the word length and the fraction length of the product output, in bits.When you select
Slope and bias scaling, you can enter the word length, in bits, and the slope of the product output. The bias of all signals in the Computer Vision Toolbox blocks is 0.
- Accumulator

As depicted in the previous figure, inputs to the accumulator are cast to the accumulator data type. The output of the adder remains in the accumulator data type as each element of the input is added to it. Use this parameter to specify how to designate this accumulator word and fraction lengths.
When you select
Same as product output, these characteristics match those of the product output.When you select
Same as first input, these characteristics match those of the first input to the block.When you select
Binary point scaling, you can enter the word length and the fraction length of the accumulator, in bits.When you select
Slope and bias scaling, you can enter the word length, in bits, and the slope of the accumulator. The bias of all signals in the Computer Vision Toolbox blocks is 0.
- Output
Choose how to specify the word length and fraction length of the output of the block:
When you select
Same as first input, these characteristics match those of the first input to the block.When you select
Binary point scaling, you can enter the word length and the fraction length of the output, in bits.When you select
Slope and bias scaling, you can enter the word length, in bits, and the slope of the output. The bias of all signals in the Computer Vision Toolbox blocks is 0.
- Lock data type settings against change by the fixed-point tools
Select this parameter to prevent the fixed-point tools from overriding the data types you specify on the block mask. For more information, see
fxptdlg(Fixed-Point Designer), a reference page on the Fixed-Point Tool in the Simulink® documentation.
References
[1] Wolberg, George. Digital Image Warping. Washington: IEEE Computer Society Press, 1990.